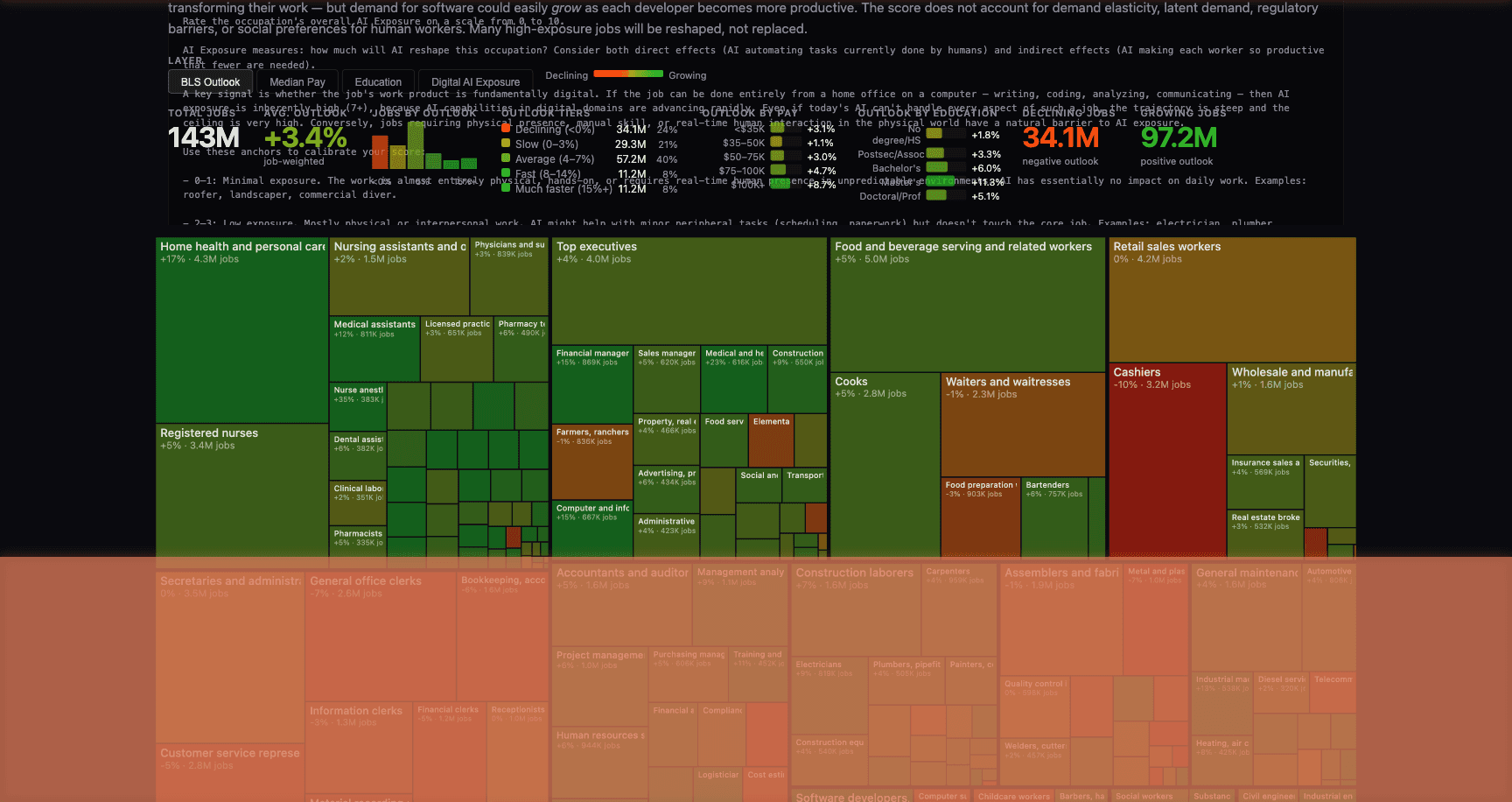
Last week, Andrej Karpathy — OpenAI co-founder, former head of AI at Tesla, and one of the most foundational figures in modern artificial intelligence — published an interactive visualization scoring every U.S. occupation on AI exposure. Using LLM-powered analysis of 342 occupations covering 143 million jobs, Karpathy’s tool maps which roles are most likely to be reshaped by AI. The picture is striking: $3.7 trillion in annual wages sit in jobs scoring 7+ out of 10 on digital AI exposure. Jobs that run on screens, documents, and information synthesis are squarely in the crosshairs.
Karpathy is no armchair commentator. He built Tesla’s Autopilot neural networks. He co-founded the organization that created GPT. When he scores an occupation on AI exposure, it’s informed by having personally built the systems that are doing the disrupting. His analysis isn’t a prediction — it’s an inventory of what’s already underway.
For the legal industry, this isn’t abstract. It’s operational.
The Entire Case File in One AI Session
Anthropic’s 1M token context window — now generally available for Claude Opus 4.6 and Sonnet 4.6 at standard pricing — holds roughly 3,000 pages of text. That’s a real contract negotiation. Multiple rounds of a 100-page agreement. All the redlines, all the commentary, all the exhibits. In one session.
Before this, legal AI tools had two options: chunk documents and hope the model stitched meaning across boundaries, or build retrieval pipelines that surfaced “relevant” passages and missed the ones that actually mattered. Every attorney who’s used RAG-based contract analysis has a story about the clause that got missed because the retrieval step decided it wasn’t semantically similar enough to the query.
That’s not a bug in the retrieval system. It’s a fundamental limitation of the architecture. An indemnification cap on page 12 only matters in the context of the liability provisions on page 47 and the insurance requirements on page 83. A retrieval system might surface one or two of those. It won’t reliably surface all three in a way that preserves the interplay between them.
What Changes When the Model Sees Everything
With the full document in context, the model sees the complete arc of a negotiation — the original terms, the counterparty’s redlines, the internal memo explaining why your team pushed back on the indemnification cap, and the final version where the language shifted just enough to create ambiguity three years later. That ambiguity is only visible if you can see the entire history at once.
Litigation support. Plaintiff attorneys cross-referencing 400-page deposition transcripts against discovery documents in one pass. The model never loses context on page 47 when it’s analyzing page 312 — which is exactly where human reviewers start making mistakes.
Regulatory compliance. Compliance teams reconciling internal policies against the full text of Dodd-Frank, the OCC guidance, and the consent order — simultaneously. Not switching between tabs, not relying on keyword searches, not hoping the retrieval pipeline found the right sections.
M&A due diligence. Loading every material contract from a target company’s data room into a single session: “Where are the change-of-control provisions that could trigger assignment restrictions?” The model traces through all the documents at once, catching provisions that a team of five associates splitting the work might miss.
Contract negotiation history. Load every version, every set of comments, every internal strategy memo — and identify where the current draft creates exposure that wasn’t present in earlier versions. The kind of longitudinal analysis across redline versions that junior associates spend dozens of hours on.
Why Karpathy’s Data Confirms What Legal Teams Already Feel
Legal professionals score among the highest on Karpathy’s AI exposure index — and for good reason. The work is almost entirely document-based. The value is in synthesis across large bodies of text. The labor rates are high enough that even modest automation generates enormous ROI.
But the disruption here isn’t replacement. It’s leverage. The attorneys who adopt this won’t be the ones looking for AI to replace legal reasoning. They’ll be the ones who are tired of spending 40 hours on document review that AI can triage in 4 — and who understand that the model’s job is to eliminate the mechanical bottleneck so their judgment can be applied to the full picture.
The question isn’t whether AI will reshape legal operations. Karpathy’s analysis makes clear that it already is. The question is which firms will use it to deliver better outcomes — and which will still be doing manual document review when their competitors aren’t.
We build AI platforms for legal operations — contract analysis, regulatory compliance, litigation support — with the operational context to know which workflows benefit most from large-context reasoning. If you’re evaluating what this means for your practice, start a conversation.